
Distributed LLMs With Petals
Some Background
Open Source Large Language Models have lunged forward in 2023, achieving results that rival those of OpenAI, Google, Meta, and Amazon. Models for programming, for fiction writing, for conversation on seemingly all topics under the sun, and for so much more. HuggingFace introduced the Transformers API Library which as of this writing has native support for over 250 model types and the nearly 300,000 public models that use them. While the big players are still leading the way in terms of model size and overall performance, it’s suddenly an era where the option is there to operate your own variants, avoiding reliance on their services and allowing for greater opportunities for narrow focus LLM exploration.
The Problem That Needs Solving
The models vary in size as much as they vary in purpose. Even with the constant leaps forward in efficiency, it’s not realistic to expect huge models to run on your home computer without Offloading. Offloading is a technique where a single computer can run a massive model by loading segments, performing the tasks against that segment, unloading it, and moving on to the next piece. It’s incredibly slow and still has its limits. While consumer GPUs can run some impressive LLMs, when you start approaching the hundred billion parameter mark even quantized language models require research/datacenter grade hardware – or do they?
Getting Started With Petals

Petals is an open source project the makes it possible to experiment with models like StableBeluga2 (70 Billion Parameters), Llama-2-70b-chat-hf (70 Billion Parameters), bloomz (176 Billion Parameters!!). Use the Petals Health Monitor to see which other models are currently running and healthy. When a model is listed as Healthy, it means there are currently peers hosting all or more than all of the model segments.
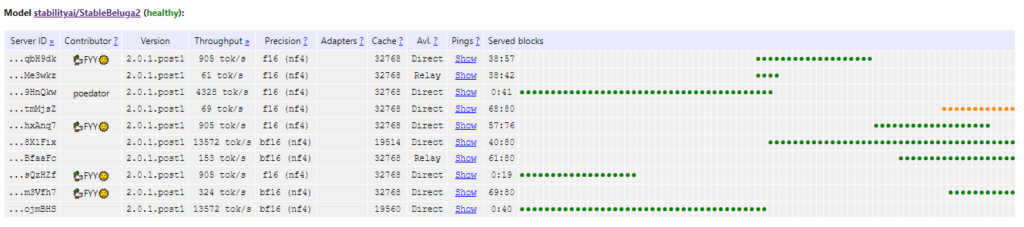
Segments? That’s the trick here – the model is chopped into blocks, and volunteers dedicate portions of VRAM to host these blocks. Whether it’s one block or fifty, every host is helping make the model available to everyone.
To give the system a shot, I wanted to run a few prompts through the Beluga2 language model. It’s easy enough to get started with Petals, so first I just set up a virtual environment for running the script.
conda create --name petals python=3.10 -y
conda activate petalsWe’ve got to install the huggingface_hub and petals packages and their dependencies.
pip install --upgrade huggingface_hub
pip install petalsCreate petals.py and paste in the following:
import torch
from transformers import AutoTokenizer
from petals import AutoDistributedModelForCausalLM
model_name = "stabilityai/StableBeluga2"
tokenizer = AutoTokenizer.from_pretrained(model_name, use_fast=False, add_bos_token=False)
model = AutoDistributedModelForCausalLM.from_pretrained(model_name)
model = model.cuda()
# start a chat session, end session by submitting an empty prompt
with model.inference_session(max_length=1024) as session:
while True:
prompt = input('Prompt: ')
if prompt == "":
break
tokenized_prompt = tokenizer(prompt, return_tensors="pt")["input_ids"].cuda()
outputs = model.generate(tokenized_prompt, max_new_tokens=256,
session=session, do_sample=True, temperature=0.9, top_p=0.6)
print("Repsonse: "+tokenizer.decode(outputs[0], skip_special_tokens=True))Note: This simple bot does not always terminate at the end of a thought. Control the response sizes with max_new_tokens and the overall conversation memory with max_length.
The Volunteer Hosting Part
So I went to fire up the script. The libraries installed, the model downloaded, roughly 2gb of local VRAM filled up and… failure to connect to model, unable to find a host with blocks 47 and 48. Looking at the health page, the model was listed as Broken and I could see the two block gap.
I was trying this from a 4gb graphics card (a Quadro P1000). Because it was only two blocks, it meant I was only going to need 2gb of VRAM for it. That left the other 2gb available for running the chatbot.
The script to provide block hosting is incredibly simple. This requires the same packages as the previous script, so if you run this from the same python virtual environment it will not require additional setup:
python -m petals.cli.run_server stabilityai/StableBeluga2 --num_blocks 2That’s it! The system will grab the model, check the available blocks, and beginning filling the gaps from the lowest numbered unserved block. Providing 10 or more blocks allows you to set a name or link to show on the health page.
The Experience of Using LLMs Through Petals
Now that I was setup, and the model was reporting as healthy, I restarted my testing script and began interacting with the model. I tried a number of script variants, adjusted inference-time parameters, tried benchmark prompts, etc.
Swapping over to Meta’s Llama 2 70 Billion parameter language model worked – though I should note that you have to request access from Meta in order to have access to the model through HuggingFace. Additionally, because it’s a protected LLM, the script needs to include a HuggingFace login call with your own API token. Llama 2 does have the decency to send a termination string after completing a thought: ^</s> Letting the model keep going beyond the end of the thought has some really interesting results though, I gotta say.
The Upsides
- Petals makes it possible to try extremely large models for free
- It is possible to run private networks, sharing the load among a group of your own PCs or a larger group of individuals looking to run a particular model.
- Compared to Offloading using Petals can be up to 10x faster
Now For The Downsides
- The generation is usually going to measure in seconds per token, so it is not a great candidate for real-time chat applications
- There are only a handful of public models available – 6 at the time of writing, with two models showing no hosted blocks and 4 reporting as healthy
- Blocks fall off and come back via other hosts, causing failures and delays
- Hosted blocks with corrupted or invalid attention caches can throw the brakes on an entire model
- There were only 12 hosts providing blocks at the time of writing, with 2 shouldering the bulk of the blocks
Conclusions
The elephant in the room is incentive. The systems don’t incentivize permanently dedicating some or all of your VRAM to the pool. For something like this to work at a larger scale there may need to be some means of incentivizing those that add GPU power to the network. Those that need to use the models consistently will want to stay connected, but they risk the interruptions that come with a hop-on-hop-off sharding approach.
The technology here is huge. The private network of GPUs option is a workable right-now use case for this. Distributing the workload for interference across any number of wildly different (but all still Cuda) devices lowers the barrier to entry for experimenting and prototyping against massive models. Suddenly you don’t need to rent multiple 80gb GPUs to test a 176 Billion parameter language model. You don’t need to pay for Google Compute Units or spend tens of thousands of dollars on gearing up at home. If it were widely adopted, and segments were run on medium to high quality GPUs, it might even serve as a viable alternative for running real-time applications at a large scale.